完成经典算法的C语言实现
[button color=”success” icon=”” url=”https://git.tanknee.cn/tanknee/DataStruct" type=””]全文源码git地址[/button]
基于磁盘的带替换选择的合并排序
先替换选择,再进行外部合并排序。
替换选择
先从源文件中读取M个数据,然后将M个数据中的最小值输出到输出文件中,再从源文件读取下一个数据。直到死区放满了或者源文件读完了再更换输出文件,直到全部处理完成,源文件与输出文件的指针交换,进行合并排序。
合并排序
从两个有数据的文件中读取第一个数据,然后比较大小,将较小的打印在输出文件上,直到这个顺串打印完成。当两个文件全部输出完后进行下一次合并排序。
合并排序结束的条件是输出文件中只有一个是有数据的,另一个没有数据。
源代码
1 |
|
测试用例
一共五十个数据。
1 | 3326 8497 13428 12105 29791 18956 18729 16025 27748 17760 11586 3912 1443 20730 6316 26020 28423 11436 9791 8752 13264 28739 8677 26431 6875 32184 511 15554 2852 25515 4100 9823 6537 17420 1131 24515 9169 4892 6604 13112 7404 17044 23362 7802 28284 11555 12819 14790 5013 22046 |
测试结果
1 | 511 1131 1443 2852 3326 3912 4100 4892 5013 6316 6537 6604 6875 7404 7802 8497 8677 8752 9169 9791 9823 11436 11555 11586 12105 12819 13112 13264 13428 14790 15554 16025 17044 17420 17760 18729 18956 20730 22046 23362 24515 25515 26020 26431 27748 28284 28423 28739 29791 32184 |
AVL树的插入
- 左旋转
- 右旋转
- 左右旋转
- 右左旋转
完全二叉树
定义:一棵二叉树中,只有最下面两层结点的度可以小于2,并且最下一层的叶结点集中在靠左的若干位置上。这样的二叉树称为完全二叉树。
特点:叶子结点只能出现在最下层和次下层,且最下层的叶子结点集中在树的左部。显然,一棵满二叉树必定是一棵完全二叉树,而完全二叉树未必是满二叉树。
插入
四种情况

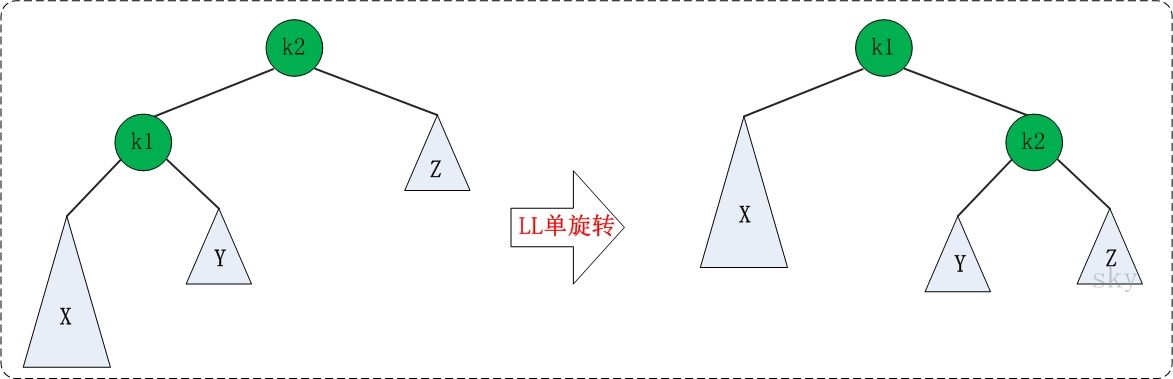
LL:
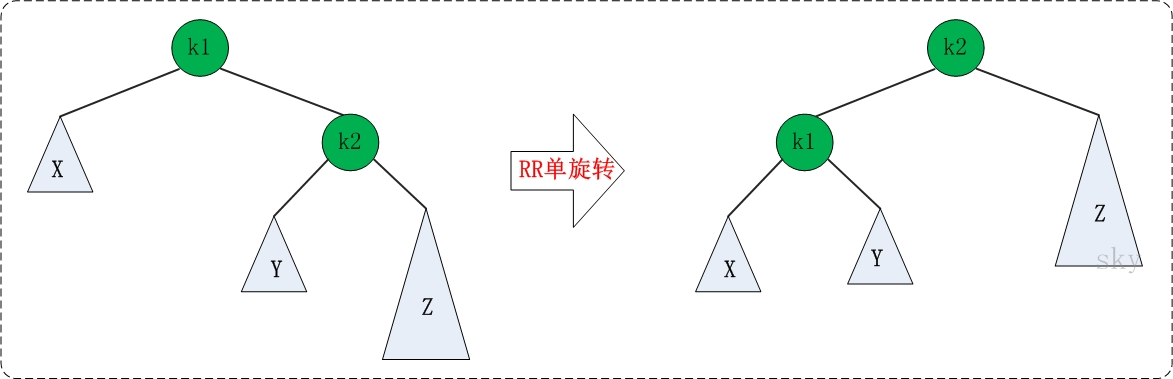
RR:
LR:

相当于进行了一次RR旋转一次LL旋转。
RL:

相当于先进行了LL旋转在进行了RR旋转。
源代码
1 |
|
测试用例
1 | Node *root = createAVLTreeNode(10,NULL,NULL); |
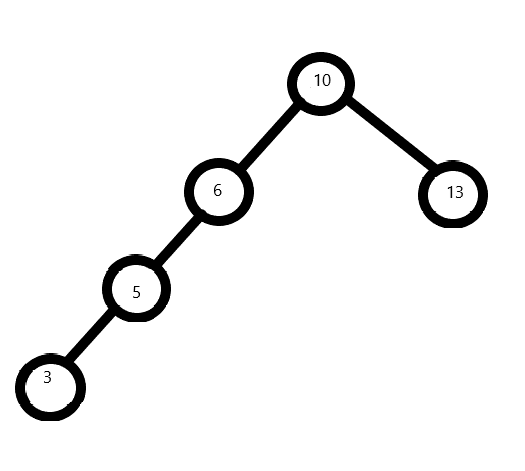
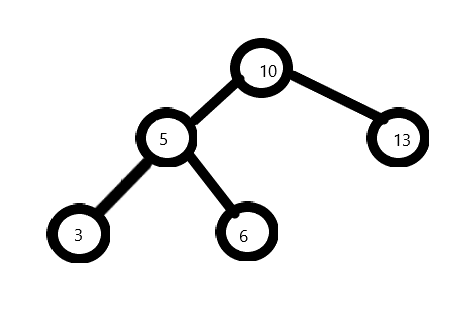
测试结果

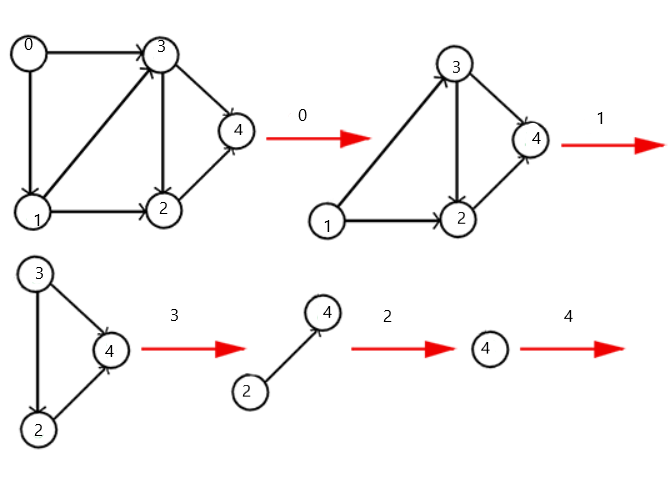
图的表示
图的拓扑排序
在图论中,拓扑排序是一个有向无环图的所有顶点的线性序列
且该序列必须满足以下两个条件:
- 每个顶点出现且只出现一次
- 若存在一条从顶点A到顶点B的路径那么在序列中,A就在B的前面!
因此只有有向无环图才会有拓扑排序,非有向无环图是没有拓扑排序的!
求拓扑排序的方法:
- 从有向无环图中选取一个入度为0(没有前驱)的顶点,并输出
- 从这个图中删除这个顶点以及所有它指向其他顶点的有向边。也就是删除所有的出边!
- 重复1,2直到图为空或者图中不再存在没有入度的顶点,如果到最后是第二种情况,那么就说明有向图中必定存在环(类似于循环结构,有出有入)
由于一个图中,在同一个时间点,可能存在有多个入度为零的顶点,因此一个有向无环图可以有多个不同的拓扑排序序列!
源代码
1 |
|
测试用例
1 | static EData gData[] = { |
测试结果

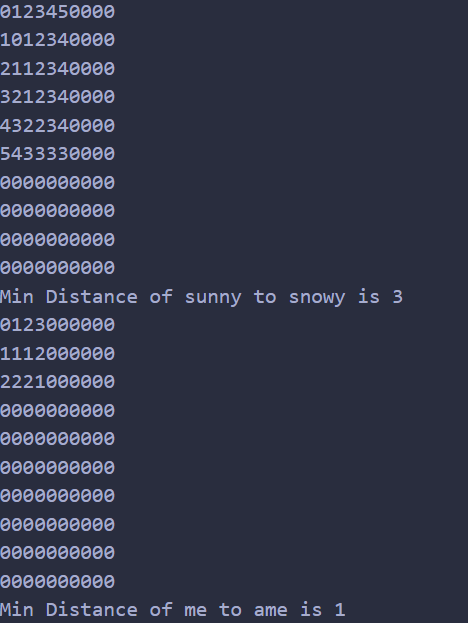
最小编辑距离

在有的文章中,替换的代价是2,而在有的文章中,替换的代价是1,本文按照代价为1的来计算。不过个人认为代价为二更加合理。
动态规划表的初始化

- D(0,j)=j,空串和长度为j的Y子串间的最小编辑距离(添加或删除对应的次数)
- D(i,0)=i,长度为i的X子串和空串间的最小编辑距离添加或删除对应的次数)
而最终的表的结果是:

在三个中取最小值作为矩阵的元素!也就是为了找出变成另一个字符串的最小代价
源代码
1 |
|
测试用例
1 | printf("Min Distance of %s to %s is %d \n","sunny","snowy",minEditDistance("sunny","snowy")); |
测试结果
表格表示
| · | s | n | o | w | y | |
|---|---|---|---|---|---|---|
| · | 0 | 1 | 2 | 3 | 4 | 5 |
| s | 1 | 0 | 1 | 2 | 3 | 4 |
| u | 2 | 1 | 1 | 2 | 3 | 4 |
| n | 3 | 2 | 1 | 2 | 3 | 4 |
| n | 4 | 3 | 2 | 2 | 3 | 4 |
| y | 5 | 4 | 3 | 3 | 3 | 3 |
所以最终的结论是sunny到snowy的最小编辑距离为3 。
| · | a | m | e | |
|---|---|---|---|---|
| · | 0 | 1 | 2 | 3 |
| m | 1 | 1 | 1 | 2 |
| e | 2 | 2 | 2 | 1 |
所以最终的结论是me到ame的最小编辑距离为1 。
霍夫曼编码

由此可以得到字符编码的前缀码,不过使用前缀码的前提是每个字符编码都不是其他编码的前缀!因此每个字符都要放在树的叶子节点上。

这样做就确保了编码没有二义性。
编码的比特数:
$$
c_i在d_i的深度出现了f_i次,那么这个字符所占用的比特数为:
\begin{equation*}
\sum_{i=1}^Nd_if_i
\end{equation*}
$$
其中深度的数值等于其编码的位数!

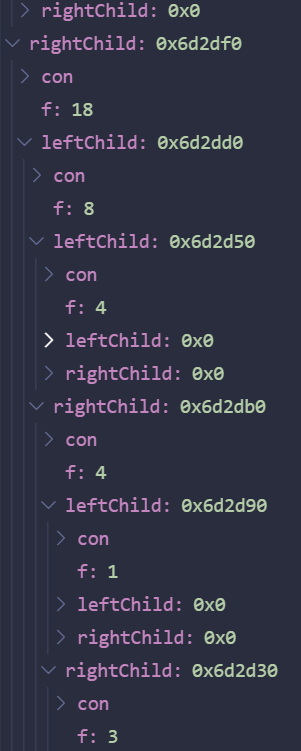
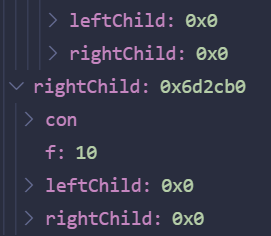
Huffman算法
算法对一个由树组成的森林进行,该森林中一共有C片叶子,也就是有C个字符需要编码。一棵树的权重等于它的树叶的频率之和。任取最小权重的两棵树$T_1$,$T_2$,并以这两棵树为子树形成新的树,将这样的过程进行C-1次,最终得到的就是Huffman编码的最优树。
为什么需要进行
C-1次: 因为森林中最开始有
C棵树,也就是一共有C棵只有一个节点的树,每一次选取都会让两棵树合并成一棵树,树的总数减少一,因此从C到1也就需要进行C-1次
示例图:

该算法每一次选取子树都是在当前条件下选取权重最小的子树,因此该算法是贪婪算法。
源代码
1 |
|
测试用例
1 | Node node_a, node_e, node_i, node_s, node_t, node_sp, node_nl,result; |
测试结果

图的表示

完成经典算法的C语言实现




