线性回归的简洁实现
线性回归
个人理解是通过建立反馈机制,逐层优化筛选最优的权重参数,以达到对最佳算法的逼近.也就是通过数值解逼近解析解.
预测二手房价格
设房屋的面积为$x_1$,房龄为$x_2$,售出价格为$y$。我们需要建立基于输入$x_1$和$x_2$来计算输出$y$的表达式,也就是模型(model)。顾名思义,线性回归假设输出与各个输入之间是线性关系:
$$
\hat{y} = x_1 w_1 + x_2 w_2 + b
$$
很明显我们能看到这是一个线性表达式,其中有两个参数会影响最终的输出结果,我们要做的事情就是找出最佳的$w_1$与$w_2$来实现对$y$的预测!
训练数据(Train Data)
我们通常收集一系列的真实数据,例如多栋房屋的真实售出价格和它们对应的面积和房龄。我们希望在这个数据上面寻找模型参数来使模型的预测价格与真实价格的误差最小。在机器学习术语里,该数据集被称为训练数据集(training data set)或训练集(training set),一栋房屋被称为一个样本(sample),其真实售出价格叫作标签(label),用来预测标签的两个因素叫作特征(feature)。特征用来表征样本的特点。
假设我们采集的样本数为$n$,索引为$i$的样本的特征为$x_1^{(i)}$和$x_2^{(i)}$,标签为$y^{(i)}$。对于索引为$i$的房屋,线性回归模型的房屋价格预测表达式为
$$
\hat{y}^{(i)} = x_1^{(i)} w_1 + x_2^{(i)} w_2 + b.
$$
损失函数(Loss Function)
在模型训练中,我们需要衡量价格预测值与真实值之间的误差。通常我们会选取一个非负数作为误差,且数值越小表示误差越小。一个常用的选择是平方函数。它在评估索引为$i$的样本误差的表达式为
$$
\ell^{(i)}(w_1, w_2, b) = \frac{1}{2} \left(\hat{y}^{(i)} - y^{(i)}\right)^2,
$$
其中常数$\frac{1}{2}$使对平方项求导后的常数系数为1,这样在形式上稍微简单一些。显然,误差越小表示预测价格与真实价格越相近,且当二者相等时误差为0。给定训练数据集,这个误差只与模型参数相关,因此我们将它记为以模型参数为参数的函数。在机器学习里,将衡量误差的函数称为损失函数(loss function)。这里使用的平方误差函数也称为平方损失(square loss)。
通常,我们用训练数据集中所有样本误差的平均来衡量模型预测的质量,即
$$
\ell(w_1, w_2, b) =\frac{1}{n} \sum_{i=1}^n \ell^{(i)}(w_1, w_2, b) =\frac{1}{n} \sum_{i=1}^n \frac{1}{2}\left(x_1^{(i)} w_1 + x_2^{(i)} w_2 + b - y^{(i)}\right)^2.
$$
在模型训练中,我们希望找出一组模型参数,记为 $w_1^*, w_2^*, b^*$ ,来使训练样本平均损失最小:
$$
w_1^*, w_2^*, b^* = \operatorname*{argmin}_{w_1, w_2, b}\ \ell(w_1, w_2, b).
$$
优化算法
当模型和损失函数形式较为简单时,上面的误差最小化问题的解可以直接用公式表达出来。这类解叫作解析解(analytical solution)。本节使用的线性回归和平方误差刚好属于这个范畴。然而,大多数深度学习模型并没有解析解,只能通过优化算法有限次迭代模型参数来尽可能降低损失函数的值。这类解叫作数值解(numerical solution)。
在求数值解的优化算法中,小批量随机梯度下降(mini-batch stochastic gradient descent)在深度学习中被广泛使用。它的算法很简单:先选取一组模型参数的初始值,如随机选取;接下来对参数进行多次迭代,使每次迭代都可能降低损失函数的值。在每次迭代中,先随机均匀采样一个由固定数目训练数据样本所组成的小批量(mini-batch)$\mathcal{B}$,然后求小批量中数据样本的平均损失有关模型参数的导数(梯度),最后用此结果与预先设定的一个正数的乘积作为模型参数在本次迭代的减小量。
在训练本节讨论的线性回归模型的过程中,模型的每个参数将作如下迭代:
$$
\begin{aligned}
w_1 &\leftarrow w_1 - \frac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}} \frac{ \partial \ell^{(i)}(w_1, w_2, b) }{\partial w_1} = w_1 - \frac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}}x_1^{(i)} \left(x_1^{(i)} w_1 + x_2^{(i)} w_2 + b - y^{(i)}\right),\\
w_2 &\leftarrow w_2 - \frac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}} \frac{ \partial \ell^{(i)}(w_1, w_2, b) }{\partial w_2} = w_2 - \frac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}}x_2^{(i)} \left(x_1^{(i)} w_1 + x_2^{(i)} w_2 + b - y^{(i)}\right),\\
b &\leftarrow b - \frac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}} \frac{ \partial \ell^{(i)}(w_1, w_2, b) }{\partial b} = b - \frac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}}\left(x_1^{(i)} w_1 + x_2^{(i)} w_2 + b - y^{(i)}\right).
\end{aligned}
$$
迭代以获取最优的参数
数据归一化和标准化
不同数值的差异对结果的影响是完全不同的.例如身高从1.6到1.8那么他的体重可能就会从50到100,可见身高变化的幅度相对体重要小得多,也就是说体重拥有更好的非线性决断能力!
因此我们需要通过归一化与标准化,让我们所有的特征值都统一到一个标准的区间!
线性函数归一化
$$
X_{normal}=\frac{X-X_{min}}{X_{max}-X{min}}
$$
- $X$原始特征数据
- $X_{min},X_{max}$所有样本中的最小值与最大值
- $X_{normal}$归一化之后的数据,在$[0,1]$之间
零均值标准化
$$
X_{normal}=\frac{X-\mu}{\sigma}
$$
- $\mu$均值
- $\sigma$标准差,一般设为1
- $X_{normal}$归一化之后的数据
数学基础附录
满秩的概念
定义一
使用初等行变化将矩阵化简为阶梯型矩阵,则矩阵中非零行的个数就是该矩阵的秩。
当矩阵的秩等于矩阵的行数时,就称该矩阵为满秩矩阵。
定义二
若该矩阵的某一r阶子式的行列式不为零,并且所有大于r阶的子式的行列式全为0,那么就称该矩阵的秩为r,使用符号记为:
$$
A_{m*n}:R(A)=r
$$
如果有以下的等式
$$
R(A)=m
$$
$$
R(A)=n
$$
那就称之为行满秩矩阵或者是列满秩矩阵!
若有$m=n$则称之为满秩矩阵,可逆矩阵,非奇异矩阵.
似然函数
对于函数$p=(x|\theta)$而言,如果我们将$\theta$设为常量,那么我们将得到一个关于$x$的函数,也就是关于$x$的概率分布.
而当我们将$\theta$当作变量,将$x$当作常量时,我们就得到了关于$\theta$的极大似然函数!
对于极大似然函数,我们可以给出一个简单的示例:
对一枚硬币随机抛掷十次,得到一个结果组:$x=HHTTHTHHHH$,也就是一组正反序列,很显然,对于抛掷硬币的实验,其分布是一组二项分布,不是正面就是反面,那么我们可以很简单的得到一个表达式:$x=\theta^7(1-\theta)^3$,对于$\theta$的不同取值,表达式也会有不同的结果,但其变量是在$[0,1]$上的,所以我们可以取遍其所有的值,获得一张表:
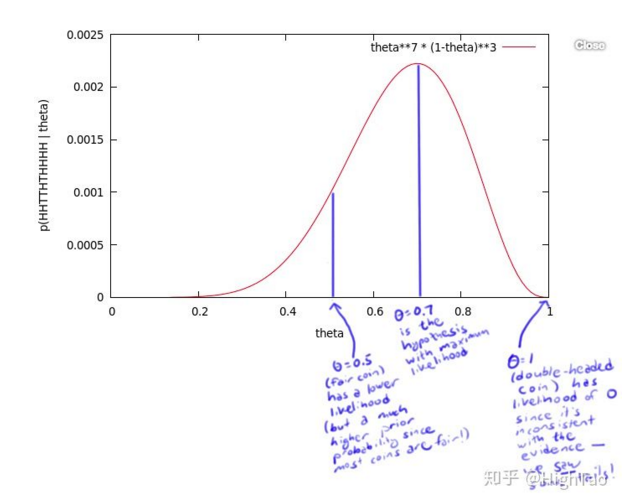
可以看到在0.7时取到最大值,也就是最大似然估计值.显然,由于样本数过少,这个值是不太可能的一个值.
所有我们可以认为,这个等式的核心意思都是在给一个theta和一个样本x的时候,整个事件发生的可能性多大
贝叶斯公式(Bayes’ theorem)
$$
P(A|B)=\frac{P(A)P(B|A)}{P(B)}
$$
凹函数与凸函数
凸函数
$$
f(\frac{x_1+x_2}{2})>\frac{f(x_1)+f(x_2)}{2}
$$
上面是一个特殊的定义,更加一般的定义是:
$$
f(ax_1+bx_2)>af(x_1)+bf(x_2)。 a+b=1
$$
那么凹函数也就是凸函数取反,即可得到。
凹函数
$$
f(ax_1+bx_2)<af(x_1)+bf(x_2)。 a+b=1
$$




